

脉冲响应有限(FIR)无限脉冲响应(IIR)滤波器是常用的数字信号处理算法特别适用于音频处理应用。因此,处理器内核在典型的音频系统中花费了很大一部分时间FIR和IIR滤波。数字信号处理器上的片内FIR和IIR硬件加速器也分别称为硬件加速器FIRA和IIRA,我们可以用这些硬件加速器来分享FIR和IIR处理任务,让核心执行其他处理任务。在本文中,我们将讨论如何在实践中使用这些加速器,使用不同的使用模型和实时测试示例。
南皇电子专注于整合中国优质电子AD代理国内领先的现货资源,提供合理的行业价格、战略备货、快速交付控制AD芯片供应商,轻松满足您的需求AD芯片采购需求.(http://www.icbuyshop.com/)

图1.FIRA和IIRA系统方框图。
图1显示了FIRA和IIRA简化方框图及其与其他处理器系统和资源的交互。
● FIRA和IIRA模块主要包含计算引擎(乘累加)(MAC)AD中国官网以及一个小的本地数据和系数RAM。
● 为开始进行FIRA/IIRA内核使用通道中特定信息的初始化处理器存储器DMA传输控制块(TCB)链。然后将该TCB写入链的起始地址FIRA/IIRA随后配置链指针寄存器FIRA/IIRA启动加速器处理控制寄存器。所有通道的配置一旦完成,就会向内核发送中断,使内核将处理后的输出用于后续操作。
● 理论上,最好的办法就是把一切都做好FIR和/或IIR任务从内核转移到加速器,允许其他操作同时进行。但在实践中,这并不总是可行的,特别是当内核需要进一步处理加速器输出,没有其他独立的任务需要同时完成时。在这种情况下,我们需要选择合适的加速器使用模型来达到最佳效果。
本文将讨论这些加速器的各种模型,以充分利用不同的应用场景。
实时使用FIRA和IIRA
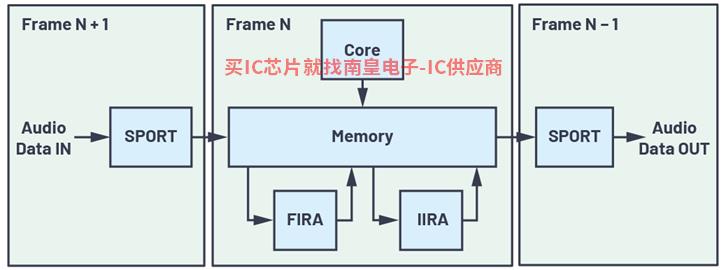
图2.典型的实时音频数据流。
图2显示了典型的实时性PCM音频数据流图。一帧数字化PCM同步串行端口的音频数据(SPORT)接收并通过直接存储器访问(DMA)发送到存储器。继续接收帧N 1时,帧N由内核和/或加速器处理,之前处理的帧(N-1)输出通过SPORT发送至DAC数模转换。
模型用于加速器
如前所述,根据应用的不同,可能需要以不同的方式使用加速器,以最大限度分担FIR和/或IIR处理任务,并为其他操作节省尽可能多的核心周期。从高的角度来看,加速器使用模型可分为三类:直接替换、拆分任务和数据流水线。
直接替代
● 内核FIR和/或IIR处理直接被加速器取代,内核只需等待加速器完成此任务。
● 该模型仅在加速器处理速度快于内核时才有效;即使用FIRA模块。
拆分任务
● FIR和/或IIR内核和加速器之间分配处理任务。
● 当多个通道可以并行处理时,该模型特别有用。
● 根据粗略的时间顺序估计,在核心和加速器之间分配通道总数,使两者大致可以同时完成任务。
● ,与直接替代模型相比,内核周期,而不是直接替代模型。
数据流水线
● 流水线可以处理内核与加速器之间的数据流,使其在不同的数据帧上并行处理。
● ,内核处理N帧,然后启动加速器处理帧。内核继续进一步并行处理加速器在上次迭代中产生的第一帧N-输出1帧。这个序列允许FIR和/或IIR处理任务完全转移到加速器,但输出会有一些延迟。
● 流水线级和输出延迟可能会增加,这取决于完整的处理链FIR和/或IIR处理级数量。
图3显示了音频数据帧如何在不同加速器使用模型的三个阶段之间传输DMA IN、内核/加速器处理和DMA OUT。它还显示了使用不同加速器的模型FIR/IIR与仅使用内核模型相比,如何增加全部或部分处理转移到加速器上的内核空闲周期。
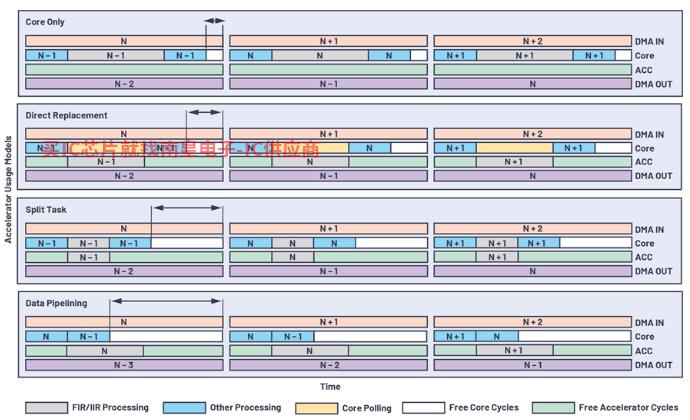
图3.加速器使用模型比较。
SHARC处理器上的FIRA和IIRA
以下AD SHARC支持片中的处理器系列FIRA和IIRA(从旧到新)。
● ADSP-214xx (例如, ADSP-21489)
● ADSP-SC58x
● ADSP-SC57x/ADSP-2157x
● ADSP-2156x
这些处理器系列:
● 不同的计算速度
● 基本编程模型保持不变,ADSP-2156x处理器上的自动配置模式(ACM)除外。
● FIRA有四个MAC单元,而IIRA只有一个MAC单元。
ADSP-2156x的FIRA/IIRA改进
ADSP-2156x是SHARC最新的处理器系列产品。它是第一个单核1 GHz SHARC处理器,其FIRA和IIRA也可在1 GHz下运行。ADSP-2156x处理器上的FIRA和IIRA与其前代ADSP-SC58x/ADSP-SC57x与处理器相比,有许多改进。
性能改进
● 计算速度提高了8倍(从SCLK-125 MHz至CCLK-1 GHz)。
● 由于内核和加速器在特殊内核结构的帮助下实现了更紧密的集成,因此减少了内核和加速器之间的数据和数据MMR访问延迟。
功能改进
● 添加了ACM尽量减少加速器处理所需的核干预。该模型主要具有以下新特点:
● 允许加速器暂停动态任务排队。
● 无通道数限制。
● 支持触发生成(主器件)和触发等待(从器件)。
● 选择性地中断每个通道。
实验结果
本节将讨论ADSP-2156x在评估板上,使用不同的加速器模型实现两个实时多通道FIR/IIR用例的结果
用例1
图4显示用例1的方框图。采样率为48 kHz,模块大小为256个采样点,拆分任务模型中使用的内核与加速器通道比为5:7。
表1显示测量的内核和FIRA MIPS与只使用内核模型相比,数量和节省内核MIPS结果。表中还显示了相应模型增加的额外输出延迟。正如我们所看到的,使用加速器和数据流水线可以节省高达335个核心MIPS,但导致1块(5.33 ms)的输出延迟。直接替代和拆分任务使用模型也可以节省98 MIPS和189 MIPS,而且没有额外的输出延迟。
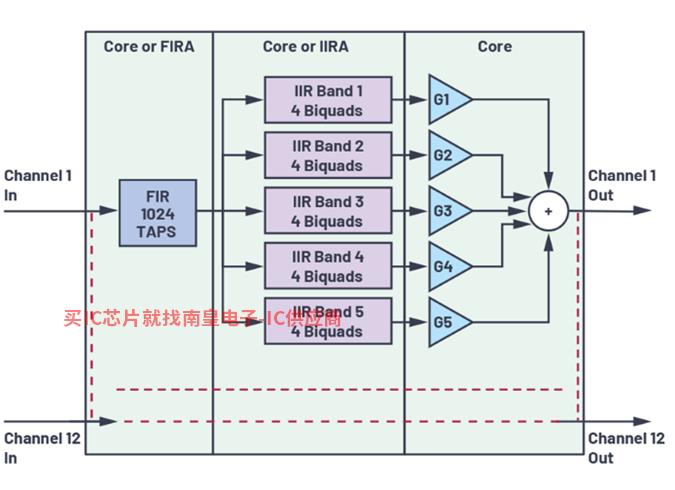
图4.用例1方框图。
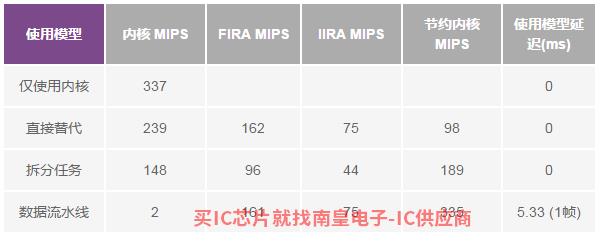
表1.用例1的内核和FIR/IIRA MIPS总结
用例2
图5显示用例2的方框图。采样率为48 kHz,模块大小为128个采样点,拆分任务模型中使用的内核与加速器通道比为1:1。
与表1一样,表2也显示了该用例的结果。正如我们所看到的,使用加速器和数据流水线可以节省高达490个核心MIPS,但导致1模块(2).67 ms)输出延迟。拆分任务使用模型可节省234核MIPS,没有额外的输出延迟。请注意,与用例1不同,用例2中的内核采用频域(快速卷积)处理,而不是时域处理。这就是为什么处理通道所需的核心MIPS比FIRA MIPS原因很少,可以直接取代使用模型实现负核MIPS节约。
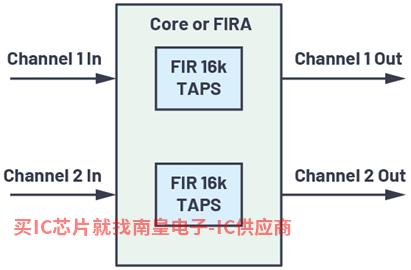
图5.用例2方框图。
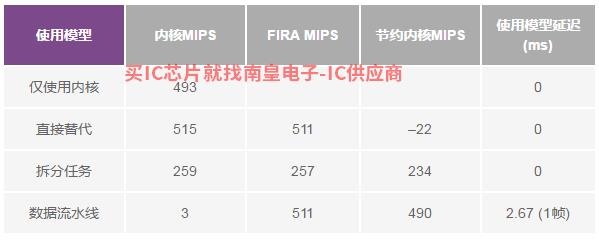
表2.用例2的内核和FIR/IIRA MIPS总结
结论
在本文中,我们看到如何利用不同的加速器使用模型实现所需的MIPS以及处理目标,以便大量的核心MIPS转移到ADSP-2156x处理器上的FIRA和IIRA加速器。
 集成电路(IC) > 线性 > 放大器 > 仪器,运算放大器,缓冲器
集成电路(IC) > 线性 > 放大器 > 仪器,运算放大器,缓冲器 集成电路(IC) > 电源管理(PMIC) > 电池充电器
集成电路(IC) > 电源管理(PMIC) > 电池充电器 集成电路(IC) > 电源管理(PMIC) > 稳压器 - 线性
集成电路(IC) > 电源管理(PMIC) > 稳压器 - 线性 集成电路(IC) > 数据采集 > 模数转换器(ADC)
集成电路(IC) > 数据采集 > 模数转换器(ADC) 集成电路(IC) > 数据采集 > 模数转换器(ADC)
集成电路(IC) > 数据采集 > 模数转换器(ADC) 集成电路(IC) > 数据采集 > 模数转换器(ADC)
集成电路(IC) > 数据采集 > 模数转换器(ADC) 射频和无线 > RF 其它 IC 和模块
射频和无线 > RF 其它 IC 和模块 集成电路(IC) > 电源管理(PMIC) > 稳压器 - 线性
集成电路(IC) > 电源管理(PMIC) > 稳压器 - 线性 电源管理IC - 稳压器 - 特殊用途
电源管理IC - 稳压器 - 特殊用途 集成电路(IC) > 线性 > 放大器 > 仪器,运算放大器,缓冲器
集成电路(IC) > 线性 > 放大器 > 仪器,运算放大器,缓冲器 开发板,套件,编程器 > 评估板 > 线性稳压器评估板
开发板,套件,编程器 > 评估板 > 线性稳压器评估板 集成电路(IC) > 电源管理(PMIC) > 稳压器 - DC-DC 开关稳压器
集成电路(IC) > 电源管理(PMIC) > 稳压器 - DC-DC 开关稳压器




- AD公司收发器通过现有的车载电缆和连接器基础设施实现高清视频
- NEC与AD合作为Rakuten Mobile提供5G O-RAN大规模MIMO无线电方案
- AD公司增强型A2B为新兴应用程序提供无与伦比的灵活性
- 高集成度 2.5A 后备电源管理器多达 2 超级电容器 提供高效充电和系统备份
- 电机控制和电源管理系统的发展趋势
- 辐射发射试验:如何避免复杂的使用EMI抑制技术实现了紧凑、高性价比的隔离设计
- 最大化Σ-Δ ADC驱动性能
- 150V 降压型 DC/DC 电池供电系统中控制器的耗电量仅为9μA
- AD 推出紧凑型 5V、10A 同步 Silent Switcher 2 降压稳压器
- NI半导体测试高峰论坛再次聚焦5G5mm波测试解决方案G时代
- AD与Momenta加快自动驾驶高精度地图产业化
- 新能源汽车继续走热,AD强势助力
